
Weboldal felépítésének vizsgálata
Bevezető Böngésző Terminál
2022. május 02.
Minden weboldal kódja egy egységes séma alapján épül fel. Ezt a sémát nevezzük HTML-nek, ami nem más mint egy leíró nyelv. A leíró nyelv nem egy programozási nyelv, mert itt nem kell programozni. Ezt úgy kell elképzelni mintha írnánk, csakhogy van megadott formátum, amit pontosan követni kell. Ahhoz, hogy weboldalt tudjunk létre hozni vagy egy meglévőnek a teljes forrását tudjuk értelmezni, tisztában kell lenni ennek a szabványnak a felépítésével. Azonban mivel ezen a blogon nem a weboldal készítéssel foglalkozunk, így elég csak pár alap dologgal tisztában lenni.
Aki többet szeretne megtudni az a W3Schools oldalán talál pontos leírásokat és mintákat.
Nézzük röviden. A HTML úgynevezett tag-ekből áll össze. Ezeket könnyű felismerni, mert mindig kacsacsőrök között vannak. Például egy sima blokk elem:<div>. Minden elemnek van egy nyitó része, ahol megmondjuk, hogy milyen elemet szeretnénk. Amiben eltérhetnek ezek az elemek egymástól, hogy vannak olyan elemek, amiknek külön független lezáró párja van és vannak olyanok, amiknek csak simán egy per jel van a végén és azzal le is van zárva.
Nézzünk először példát arra, ha van záró párja: <div>Tartalom </div>. Itt egy egyszerű blokk elemet hoztunk létre, aminek van tartalma. Láthatjuk, hogy ilyen esetben a tartalom a két összetartozó rész között helyezkedik el.
Nézzünk olyat is ahol nincs párja, tehát egyedüli elem. Ilyen például a sortörés: <br/>. Amikor egy ilyen kódot helyezünk el egy weboldalon, ott egy sima sortörés jön létre. Az ilyen és ehhez hasonló elemeknek nincs szüksége tartalomra ezért nincs is záró párja.
Bármilyen sima weboldalt böngészve ezzel a sémával találkozhatunk. Bár azt meg jegyezném, hogy az új elfogadott sztenderdek szerint a lezáró pár nélküli tag-eknél nem kötelező a / jel használata, de ettől függetlenül szinte minden weboldalon ott van.
A feldolgozás során a tag-ek tartalmára lesz szükségünk vagy esetleg valamilyen paraméterekre. A paraméterek olyan információk, amik külön meg vannak adva ezeknél az elemeknél. Ilyen paraméter például az azonosító, ez számunkra majd nagyon fontos lesz, ezért kezdtem is ezzel. Az azonosítóval lehet hivatkozni egy-egy elemre és így tudjuk kinyerni a tartalmát vagy további más paramétert. Az azonosító az úgynevezett id paraméter. Amit itt fontos megjegyezni, hogy ebből a szabvány szerint csak egy darab lehet minden oldalon, tehát ha találunk id paramétert, akkor feltételezhetjük, hogy csak és kizárólag arra a speciális elemre utal, amiben megtaláltuk. A másik ilyen fontos paraméter a class, ami egy osztályszintű megnevezés. Ez is csak egy azonosító, ami az elem beazonosítására szolgál, azonban abban eltér, hogy több is van belőle. Ez viszont jó nekünk, mert azonos objektumok kapják ugyanazokat az osztályokat. Későbbiekben ezeket sokat fogjuk használni, hogy ezáltal tudjunk hivatkozni az oldal elemeire.
Na de nézzünk hozzá példát is. Nyissuk meg a böngészőt és mintának töltsük be a BBC oldalát. Láthatjuk, hogy cikkek vannak rajta egységesen. Nézzük meg a forrását, amit az oldalon a jobb gomb megnyomás után a feljövő menüből az oldalforrás menüpontot választva már böngészhetünk is. A forrásban láthatjuk, hogy nagyon sokfelé tag található benne, és ezeknek az elemeknek a különböző paraméterit is látjuk. Fontos, hogy ne ijedjünk meg, ezt nem kell végig böngészni, se megérteni (ha valaki szeretné akkor csak nyugodtan) . Minden modern böngészőben van segítség hozzá, ha mi csak egy egy általunk kinézett elem felépítését és struktúráját szeretnénk elemezni.
Térjünk vissza az oldalra és nézzük ki, melyik elemek keltették fel az érdeklődésünket. Én szeretnénk több információt az aktuális cikkek címeiről, így ezeket az elemeket szeretném megvizsgálni. Nyissuk meg a kis alkalmazást, ami segít nekünk. Ehhez nincs más dolgunk, mint hogy a böngészőben nyomjuk meg az F12 billentyűt, és megnyílik a böngésző terminálja. Én a Firefox böngészőt használom, és a példáimat is ezen fogom bemutatni. Nagy eltérés nincs a böngészők között, de a megjelenítésben előfordul némi különbség.
Minden terminál legtetején a menüsor egy ikonnal kezdődik. Ennek az a funkciója, hogy ki tudjunk vele jelölni egy elemet a weboldalon, és azt ki tudjuk elemezni. Ezzel az eszközzel fogunk most dolgozni, és a későbbiek során is nagyon sokat fogjuk használni.
A eszköz működéséről röviden: Rákattintás után (amit úgy jelez, hogy szép kék lesz) a weboldalon ahogy húzzuk az kurzort, látjuk, hogy különböző elemeket jelöl ki. Már ennél a sima kijelölésnél is lehet látni, hogy milyen blokkokból épül fel az adott oldal. Amint megtaláltuk a saját elemünket, a vizsgálatához rá kell kattintatni, amikor szép kék hátteret kapott. Tegyük ezt az adott oldalon egy cikk címénél és nézzük, mit tudunk meg róla.
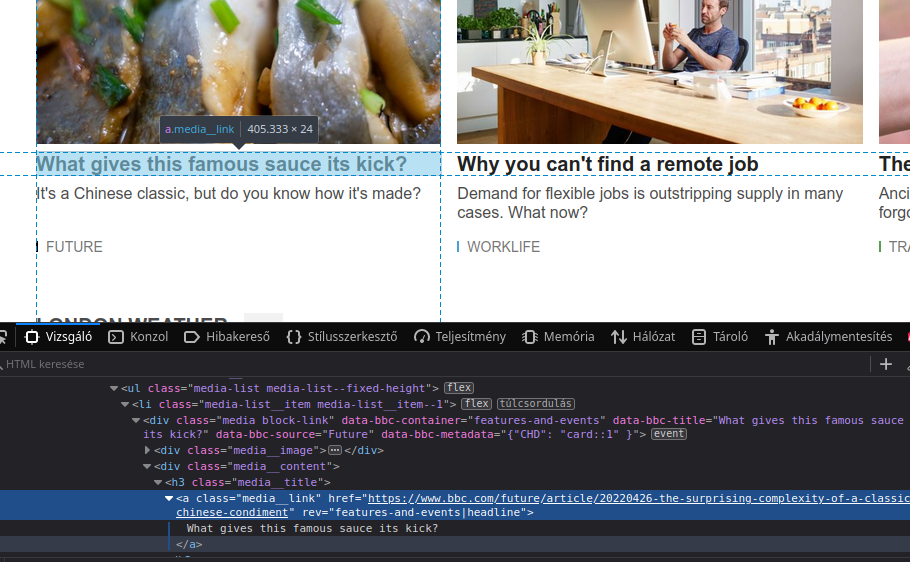
Kattintás után alul az Vizsgálóban az az elem lesz kiemelve, amit kiválasztottunk, így van lehetőségünk megvizsgálni az elemeket. Röviden egy nézzük mit is látunk a címnél: <a> elem, az ilyen elemeket linkek, amiknek ebben az esetben hivatkozásuk is van. Ezt egy href paraméterrel kell megadni. Itt konkrétan azt a linket láthatunk, amire irányít minket a oldal a kattintás után. Amikor jobban megnézzük láthatjuk, hogy van egy class paramétere ennek az elemnek, ami nagyon fontos lesz nekünk. Nyugodtan feltételezhetjük, hogy minden ilyen címnek van egy ilyen osztálya. A paramétereken túl látjuk, hogy az elem tartalma (tag-ek között) az a tényleges cím, amit az oldalon is látunk kiírva.
Következő lépés, hogy el kell döntenünk, hogy elég információt gyűjtöttünk-e az adott elemről. Könnyen lehet, hogy úgy érezzük, nem elég pontos a meghatározás és szeretnénk biztosra menni, hogy más elem nem kerül a találatba. Ebben a konkrét esetben a sima osztály meghatározás elég pontatlan, hisz média link lehet sokkal több is az oldalon. Jobban meg figyelve láthatjuk, hogy ezek a linkek benne vannak egy másik blokkban, ami egy <h3>-as tag (Header 3, az az 3. szintű fejléc) és az osztálya media__title. Ez így érezhetően tökéletes lesz az esetünkben, hiszen nekünk a címek kellenek és ez egyértelműen arra utal.
Foglaljuk össze. Van egy <h3>-as elemünk, aminek pontos egyértelmű az osztály meghatározása (media__title). Ezen belül van egy <a> hivatkozás elem, ahol a linket is és a címet is megkapjuk a vizsgálat során.
Ez így szép és jó, de mit tudunk vele kezdeni? Itt még szükségünk van arra, hogy miként lehet adott elemekre hivatkozni és információt kikérni a elem vizsgálón kívül.
Ahogy korábban szó esett róla, az id az egyedi azonosító. Erre úgy tudunk hivatkozni, hogy a paraméternek megadott érték kap egy # jelet az elejére. A BBC oldalt használva mintának, a híreket tartalmazó elem egy <div> tag ( sima blokk elem):
<div id="page" role="main" class="content" data-wwhp-module="images, media">Láthatjuk is, hogy jó sok paramétert kapott, de köztük id-t és class-t is. Amennyiben az adott elem id azonosítójára szeretnénk hivatkozni, akkor az alábbi formában tehetjük:
#pageUgyanígy az osztályoknak is van egy ilyen előtagja, ami nem más mint a pont (.). A cikkcímekre hivatkozva az alábbi formát használjuk:
.media__titleEzen túl még egy fontos dolog marad, amikor egy sima tag-re szeretnénk. Itt annyi a különbség, hogy nincs semmi előtagja csak simán hivatkozunk rá. Nézzünk pár példát:
div
p
aLegvégül pedig a legtöbbet használt eset, az a különböző hivatkozásoknak a keveréke, amikor a megfelelő azonosítókat egymás utána tesszük. Ezt kicsit úgy lehet elképzelni, mint ha azt mondjuk, hogy Péter-ből sok van. Viszont, ha Pétert keresünk akinek a vezetékneve mondjuk Kovács, akkor Kovács Péterből már jóval kevesebb van. Ezt is tudjuk tovább szűrni, ha az anya neve Éva. Nézzük, ez hogy is néz ki a BBC-s példában.
Keressük azokat a <a> hivatákozás tag-eket, akiknek az osztálya media__link.
a.media__linkEzzel még ne elégedjünk meg, szűrjünk tovább. Csak azok a linkek kellenek, akik a media__title osztályok gyermekei.
.media__title a.media__linkEzzel már nagyon leszűrtük a találatokat, azonban ha szeretnénk biztosra menni, akkor megmondhatjuk még, hogy a page azonosítóval rendelkező dobozon belüli elemekre van szükség.
#page .media__title a.media__linkNézzük meg, ez hogy néz ki a gyakorlatban, mert ez így tényleg nagyon száraz. Térjünk vissza a böngésző terminálba és válasszuk ki a Konzol fület.
Itt mindenféle üzenetek fogadhatnak minket, amiket a böngésző vagy az oldal ír ki. Lehetnek különböző oldalhibák vagy információk, ezzel nem kell most foglalkozni, csak zavaró tényező lenne. Ha tényegesen zavar bárkit is, akkor a kuka ikonnal ki lehet törölni ezeket, és akkor üres konzollal lehet kezdeni a munkát.
Ez egy olyan felület, ahol parancsokat tudunk kiadni a böngészőnek az adott oldallal kapcsolatban. Itt a lehetőséget tárháza iszonyatosan nagy. Mi csak pár nagyon alap példát nézünk meg.
Elsőre kérjük le az összes címet tartalmazó link elemet.
document.querySelectorAll("#page .media__title a.media__link");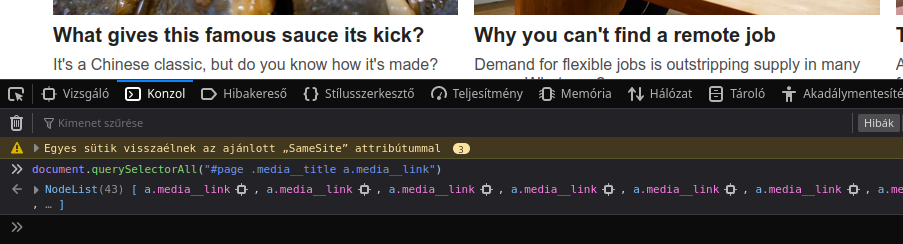
Rendben le is futott, de mi történt valójában, és mi az a querySelectorAll? Röviden a parancsról: Az adott oldalról (document-ből) keresünk elemeket, ezért hívjuk meg a querySelectorAll függvényét. Ez a függvény az általunk megadott feltételeket futtatja le és visszatér egy listával. Ez a lista tartalmaz minden olyan elemet, ami megfelelt a kritériumainknak. Az én esetben a futtatással azt látom, hogy 43 darab olyan cikk van az oldalon, ami átmegy a szűrőn.
Megjegyzés: A querySelectAll függvénynek van egy kis testvére a querySelect. Ez azért fontos, mert ez csak egyetlen elemmel tér vissza, és az is a legelső lesz, ami az oldalon megtalálható és megfelelt a kritériumoknak. Akkor használjuk, ha ténylegesen csak az első és egyetlen elemet szeretnénk megkapni.
Most van egy listánk, a következő feladat az, hogy ezt dolgozzuk is fel. Most jön egy kis JavaScript programozás. Végig kell mennünk a listán és ki kell kérni minden elemnek egy tulajdonságát. Jelen esetben a tartalmát fogom kiíratni a konzolba sima szövegként. Azt fogjuk látni, hogy ténylegesen csak a címek fognak megjelenni egymás alatt.
document.querySelectorAll("#page .media__title a.media__link").forEach(link => console.log(link.innerText))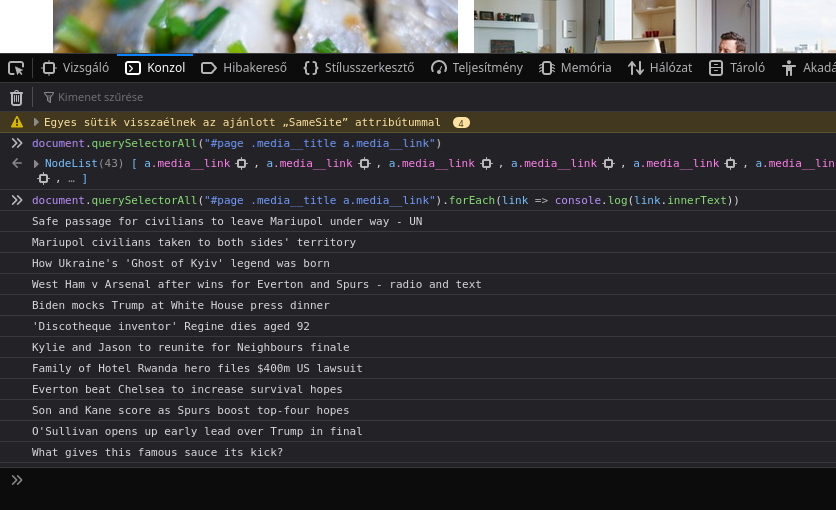
Kikérjük mind a 43 hivatkozást a korábban is használt módszerrel (querySelectorAll), majd egy forEach nevű függvénnyel végigmegyünk egyesével az összes elemen. Itt a függvényen belül egy egyszerű console.log() függvénnyel kiíratjuk az összes megtalált elem szöveges tartalmát (innerText). Ennek eredményeképpen megjelent a terminálban 43 sor, egyesével a cikkek címeivel.
Ezzel a módszerrel bármilyen adatot ki lehet nyerni egy weboldalról és azt akár további feldolgozásra is elő lehet készíteni.
További hasonló bejegyzések ebben a kategóriában:


