
Adat átalakítás folytonos szövegből Excel táblázatba
Adat Adat átalakítás Python Excel
2023. május 14.
Adat átalakítás folytonos szövegből Excel táblázatba
Bármikor előfordulhat, hogy kapunk egy folytonos szöveges állományt. A jobb esetben ez szeparálva van vagy, ami rosszabb, hogy csak ömlesztve és nekünk kell keresni, hogy mi alapján lehet tagolni a sorokat.
Van megint egy példám, amin keresztül a folyamatot be tudom mutatni, ez is egy olyan példa amit a mindennapokból hozok. Van egy feladat, hogy a látogatottságról kell különféle kimutatást készíteni. Ehhez kapunk egy sima szöveges állományt, ami valójában egy aggregált log állomány a hozzáférési állományból, mert úgy gondolták az eredeti biztos nehezebben érthető….
A logok formája
Annak érdekében, hogy jobban megértsük, nézzük meg hogy néz ki egy átlagos log állomány pár sora. Fontos, hogy itt csak tényleges access log sorairól van szó, ami nem tartalmazza a hibás kéréseket és még számos további lekérést.
A mintát az alábbi oldalról hoztam: https://www.ossec.net/docs/log_samples/apache/apache.html
192.168.2.20 - - [28/Jul/2006:10:27:10 -0300] "GET /cgi-bin/try/ HTTP/1.0" 200 3395
127.0.0.1 - - [28/Jul/2006:10:22:04 -0300] "GET / HTTP/1.0" 200 2216Amit itt látunk egy előre definiált séma alapján felépülő bejegyzés. A log minden sora illeszkedik a definiált struktúrára. Ami nekünk itt fontos, hogy tartalmazza az IP címet, ahonnan a kérés érkezett, annak a pontos időpontját (CLF formátumban). Ezen túl benne van, hogy milyen típusú kérés érkezett (GET, POST, HEAD stb.) és ami nagyon fontos, hogy pontosan melyik url-t kérték le. Ezen túl is van több informatív adat benne, de nekünk most ennyi bőven elég ahhoz, hogy csak bepillantsunk és megértsük, miből készült az általunk kapott állomány.
A forrásunk
Az előző kis betekintés után nézzük akkor mit is kapunk pontosan:
/posts/browser-weboldal-felepitesenek-vizsgalata
1230 2023/01
1532 2023/02
1942 2023/03
1272 2023/04
/posts/node-adatok-weboldalrol-elso-resz
1980 2023/03
2502 2023/04
/posts/node-cli-pdf-allomany-egyesitese
873 2023/01
1034 2023/02
954 2023/03
1079 2023/04Jöhet az elemzés, láthatjuk, hogy van egy url és utána minden sorban az adott hónapban elért látogatók számát az év/hónap opcióval kiegészítve.
A célunk
A cél hogy egy Excel táblázatot csináljunk ebből méghozzá úgy hogy az A oszlopban a linkek legyen, a fejlécek pedig az év/hónap.
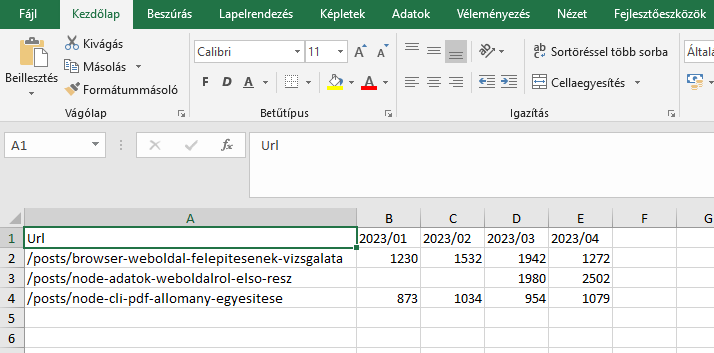
Látható, hogy ehhez minden sort fel kell dolgozni és megtalálni azt a formázási mintát, amivel tudjuk tagolni magunknak. Látható, hogy ahol nem hivatkozás szerepel ott a számok előtt vannak szóközök. Ahol nincs szóköz az tényleg hivatkozás. Ezzel meg is van tagolás és ezt a szemantikát már csak át kell ültetni kódba.
Előkészületek
Szedjük össze akkor mit tudunk és mire van szükségünk. Első, amit biztosan tudunk, hogy a kimenet egy excel táblázat lesz. Ehhez keresni kell egy olyan csomagot, ami megfelel a mi igényeinknek. Szerencsére van egy nagyon jó XLSXWrite nevű csomag, ami tökéletes. Telepítsük és használjuk.
https://pypi.org/project/XlsxWriter/
pip install XlsxWriterHozzuk létre a scriptünket. Ezt egyszerűen logToXlsx.py-nek fogom hívni. Majd import-al használjuk is a csomagot.
import xlsxwriterNevezzük meg azt az állományt, amiből dolgozunk és nyissuk meg. Illetve ne felejtsük el jelezni a felhasználónak, hogy dolgozni a szoftver.
print("Adatok feldolgozása folyamatban!")
#Eredmények beolvasása
f = open(log.txt')
lines = f.readlines()
Ezzel az alapok meg is vannak és neki lehet állni a sorok feldolgozásának.
Maga a feldolgozás
A feldolgozás során egyesével végig kell menni minden soron. A végeredmény szempontjából szükségünk lesz minden dátumra, ami csak szerepel az állományba. Ennek hozzunk létre egy listát, amibe bele tudjuk őket tenni.
keyList = []
data={}
lastKey=False
Amire még szükség van az egy lista, amibe az kulcsokat tehetjük és ezen túl még egy objektum, ahol kulcsokkal tudjuk tárolni az értékeinket. Plusz még egy változó, amivel tudjuk ellenőrizni, hogy utolsó kulcs e az aktuális.
Az első teendőnk, hogy az összes dátumot, ami szerepel benne azt ki kell válogatni, de szigorúan csak egyszer tehetjük be a kulcsok közé. Hiszen az Excel fejlécben is csak egyszer szeretnénk látni.
Ehhez nincs más dolgunk, mint végig menni az összes soron és megnézni, hogy mivel kezdődik, ha nem szóköz akkor az egy hivatkozás lesz és később foglalkozunk vele, mivel még nem tudjuk, hogy pontosan hány oszlopunk lesz ezért nem írhatjuk még ki.
for line in lines:
if not line.startswith(" "):
lastKey=line.strip()
data[lastKey] = []
continue
if lastKey == False:
print("Hiba, nincs állomány név: {}".format(line))
exit()
dataValue = line.strip().split(" ")
if not dataValue[1] in keyList:
keyList.append(dataValue[1])
data[lastKey].append([dataValue[1], dataValue[0]])
Elemezzük pontosan mi is történt. Megnézzük, mivel kezdődik a sor, amennyiben szóközzel, akkor a következő teendőnk megtisztítani a felesleges szóközöktől. Ezt a strip() függvénnyel tudjuk megoldani és az eredményét eltesszük mint utolsó kulcs, hiszen ez a hivatkozás szerepel a logban, tehát be kell tenni majd az Excelbe. Ezért az adat objektumokban az adott kulcshoz létrehozunk egy üres listát, amibe később majd bele tudjuk tenni a látogatásokat számát az adott hivatkozáshoz. Végezetül a continue metódussal folytatjuk a ciklust, mert minden rendben volt.
Azonban ha nem szóközzel kezdődik és az utolsó érték se volt beállítva, tehát a változónk még mindig False értéken áll, akkor az állományunk nem valid, mert az első sora nem egy hivatkozás, hanem már egy látogatási érték. Ekkor hibát kell kiírni és befejezni a program futását.
Van még egy utolsó eshetőség, ha már van kulcsunk és az aktuális sor egy elérési sor a dátummal, akkor azt is fel kell dolgozni. Első lépés a sort megtisztítani és szétválasztani a két értéket. A tisztitást továbbra is a strip() függvénnyel végezzük, utána pedig a split() függvénnyel szét vágjuk a szöveget és listává alakítjuk, jelen esetben a szóköznél. Így kapunk egy két elemű listát, azért csak kettő mert a strip az elejéről és a végéről is levette a felesleges szóközöket. A listánk első elem a látogatottsági szám, a második pedig a dátum.
Ha ezzel megvagyunk ellenőrizzük, hogy létezik-e már ez a dátum a kulcsok között, ha nem akkor bele kell tenni. Majd legvégül az így kapott látogatási adatot az idővel együtt beletesszük az adat listába. Itt fordított sorrendbe tettem bele előre kerül a dátum és utána a érték.
Ezzel a teljes adatfeldolgozás végére értünk. Megvan az összes év/hónap ami csak szerepel a logokban és az adatok is fel vannak töltve. Két teendőnk maradt. Sorba rendezni a kulcsokat, mert az Excelbe is úgy szeretnénk látni.
keyList.sort()Az utolsó teendő, pedig az Excel előállítása.
Az Excel kimenet generálása
Itt az első dolgunk létrehozni az Excel állományt és hozzá adni egy új fület
workbook = xlsxwriter.Workbook('log-analytics.xlsx')
worksheet = workbook.add_worksheet()Majd tegyük ki változóba, hogy melyik sor és oszlop legyen az első
row = 0
col = 0Írjuk be az A1-es cellába hogy az A oszlop az Url oszlopa.
worksheet.write(row,col,"Url")Majd ugyanebben a sorban a többi mezőt is töltsük ki a dátumokkal, amiket már sorba rendezve várják ezt a listában.
# Hogy az B oszlopba kezdődjön.
col += 1
#Évek feltöltése a kulcsok alapján
for date in keyList:
worksheet.write(row,col,date)
col +=1
Itt nem történik más, mind a rendezett tömbön végig megy és minden értéket beír az 1-es sor következő cellájába.
Ha ez megvan, növeljük a sort, ahol az adatok kezdődnek majd.
row += 1Majd írjuk be az adatokat szépen sorban.
for url in data.keys():
worksheet.write(row, 0, url)
for values in data[url]:
col = keyList.index(values[0]);
worksheet.write(row,col+1,int(values[1]))
row +=1Végig megyünk az adat listán és mivel a kulcsok az url-ek voltak így az A oszlopba egyből be is írhatjuk az elérési utat.
A listában viszont a tényleges elérések vannak, ahol az első elem a dátum a második pedig az elérési szám. Nincs más teendőnk, mint kikérni, hogy hányadik elem a dátumok közül és ehhez az értékhez plusz egyet adva megkapjuk melyik az ő oszlopa. (Azért kell a plusz egy mert az első oszlopban a hivatkozás van ezért az egész egy oszloppal elvan csúsztatva.) Innentől kezdve már csak bele kell írni abba a cellába az értéket.
Ha ezzel megvagyunk, be kell zárni az Excelt és jelezni, hogy kész van.
workbook.close()
print("Excel sikeresen kiírva!")
A program tényleg kész van és működik, de azért ráfér egy kis finomhangolás és szépítés. Legalább két dolgot vigyünk bele, hogy a meneti és a kimeneti állományok nevét kérje paraméternek, hogy ne legyen beleégetve semmi. Erre érdemes mindig oda figyelni, hogy ha tehetjük, akkor semmi olyan ne legyen a kódban, ami paraméterezhető. Úgy szoktuk mondnai, hogy ne legyen semmi beégetve a kódba, az csak kód legyen.
Akkor nézzük, mi változott.
import sys
import xlsxwriter
#Eredmény állomány nevének kiolvasása
if len(sys.argv) > 1:
result=sys.argv[1]
else:
exit("A forrás állomány megadása kötelező! (Első paraméter)")
# Cél állomány megnevezése
if len(sys.argv) > 2:
target=sys.argv[2]
else:
target=result+".xlsx"
Az elejére be kell tenni egy import-ot, hogy a sys csomagot tudjuk használni, ebben található a argv metódus, amivel ki kérhetjük a temrinálban beírt érékeket. Majd meg nézzük, hogy nagyobb e mint a tömbb mint 1 és ha igen, akkor meg kapta a forrás állomány nevét, viszont ha nem akkor hibával lekell állítani a program futását, hiszen így nem tudunk mit feldolgozni. Amikor megkapjuk, akkor el tároljuk egy változóban, amit a késöbbiek során meghívunk. Ezután megnézzük, hogy kaptunk e kiementi állomány nevet. Abban az esetben, ha igen, akkor ezt is változóba tesszük, ellenben ha nem akkor most nem kell hiba üzenet, hiszen a forrás nevét tudjuk használni. Ezt a nevet csak ki kell egészíteni egy kiterjesztéssel és így már menthető is. Ezzel a megoldással nem lett kötelező paraméter a kiement.
Nézzük mi változott még.
#Eredmények beolvasása
f = open(result)workbook = xlsxwriter.Workbook(target)Ezen túl még a végeredmény visszajelzést is módosítottam, hogy pontosan ki írjuk milyen néven történt mentés.
print("Excel sikeresen kiírva a(z) "+target+" állományba!")Ezzel a pár soros módosítással az egész programot dinamikussabbá tudtuk tenni, hiszen nincs szükség mindig megeggyező állomány nevekre és a kimenet is mindig egyedi. Az ilyen megoldással nem a kód lett tisztább, de szintén sok időt lehet nyerni vele.
Lássuk egyben az egész kódot akkor
import sys
import xlsxwriter
#Eredmény állomány nevének kiolvasása
if len(sys.argv) > 1:
result=sys.argv[1]
else:
exit("A forrás állomány megadása kötelező! (Első paraméter)")
# Cél állomány megnevezése
if len(sys.argv) > 2:
target=sys.argv[2]
else:
target=result+".xlsx"
print("Adatok feoldolgozása folyamatban!")
#Eredmények beolvasása
f = open(result)
lines = f.readlines()
keyList = []
data={}
lastKey=False
# átalakítása json fomrába - kiadvány a kulcs, tömb értékkel benne további tömb, dátum és érték páros
for line in lines:
if not line.startswith(" "):
lastKey=line.strip()
data[lastKey] = []
continue
if lastKey == False:
print("Hiba, nincs állomány név: {}".format(line))
exit()
dataValue = line.strip().split(" ")
if not dataValue[1] in keyList:
keyList.append(dataValue[1])
data[lastKey].append([dataValue[1], dataValue[0]])
workbook = xlsxwriter.Workbook(target)
worksheet = workbook.add_worksheet()
row = 0
keyList.sort()
worksheet.write(row,0,"Url")
col = 1
#a header évek feltöltése
for date in keyList:
worksheet.write(row,col,date)
col +=1
row += 1
# adatok kiírása
for url in data.keys():
worksheet.write(row, 0, url)
for values in data[url]:
col = keyList.index(values[0]);
worksheet.write(row,col+1,int(values[1]))
row +=1
workbook.close()
print("Excel sikeresen kiírva a(z) "+target+" állományba!")További hasonló bejegyzések ebben a kategóriában:


